 Vitalii Holben
Vitalii Holben
How to Take a Website Screenshot with Go (chromedp, API)
Learn how to capture website screenshots with Go using two approaches: chromedp for local browser automation and a screenshot API for production. Working code, full-page captures, mobile viewports, and honest comparison.

Today I want to show you how to take website screenshots with Go. When I first looked into this, I assumed Go wouldn't have much to offer compared to Python or Node.js, where Playwright and Puppeteer are already the default tools. Turns out Go has a solid library called chromedp that talks to Chrome directly through the DevTools Protocol, with zero external dependencies.
In this guide I'll walk through two approaches: chromedp for local browser automation and a screenshot API for production use. We'll start with a basic script and work our way up to full-page captures, custom viewports, mobile emulation, element screenshots, and batch processing multiple URLs.
What you'll need
Before we start, make sure you have Go 1.21 or newer installed:
go versionYou'll also need Google Chrome or Chromium. chromedp runs it in headless mode behind the scenes. Check if it's there:
google-chrome --version
# or
chromium --versionIf Chrome is in place, let's set up the project:
mkdir go-screenshots
cd go-screenshots
go mod init go-screenshotsMethod 1: chromedp
chromedp is a Go library for controlling Chrome through the DevTools Protocol. No external dependencies, no WebDriver wrappers, just direct communication with the browser over CDP. For Go developers it's the most natural choice, since it's written in pure Go.
Installation
go get github.com/chromedp/chromedpThat's all you need. No separate driver download, no 400 MB Chromium binary. chromedp finds the Chrome installation on your system automatically.
Basic screenshot
Create a file called main.go:
package main
import (
"context"
"fmt"
"log"
"os"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var buf []byte
if err := chromedp.Run(ctx,
chromedp.Navigate("https://news.ycombinator.com"),
chromedp.CaptureScreenshot(&buf),
); err != nil {
log.Fatal(err)
}
if err := os.WriteFile("hackernews.png", buf, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: hackernews.png")
}Run it:
go run main.go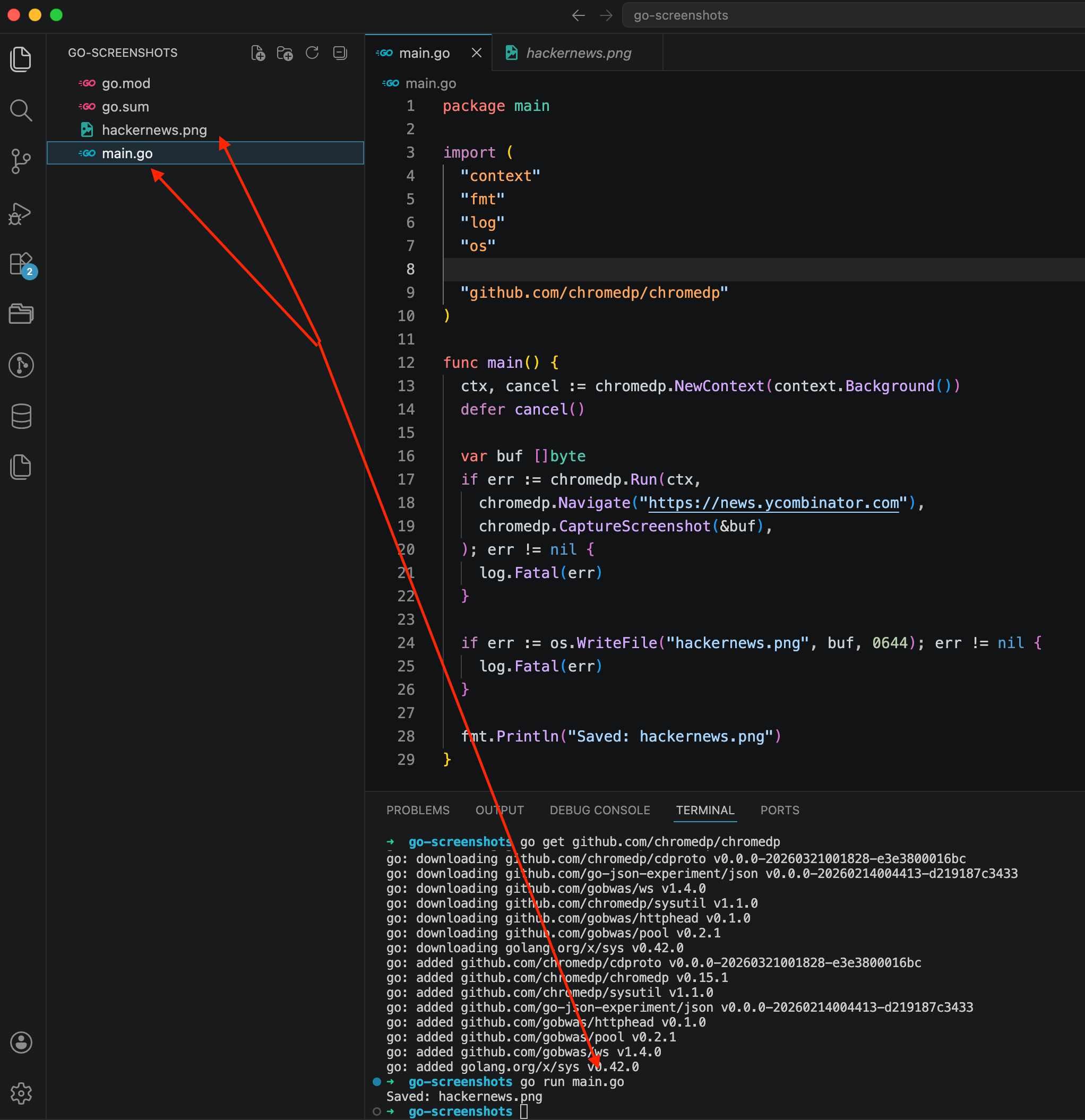
The terminal shows the whole process: go get pulled chromedp and its dependencies, go run main.go launched the script, and a couple of seconds later it printed Saved: hackernews.png. The file appeared in the sidebar on the left. The code in the editor is 29 lines, nothing extra.
Notice the pattern here: chromedp.NewContext creates a context, chromedp.Run accepts a chain of actions (navigate, capture), and errors are handled the standard Go way. No magic.
Now let's open the file itself:
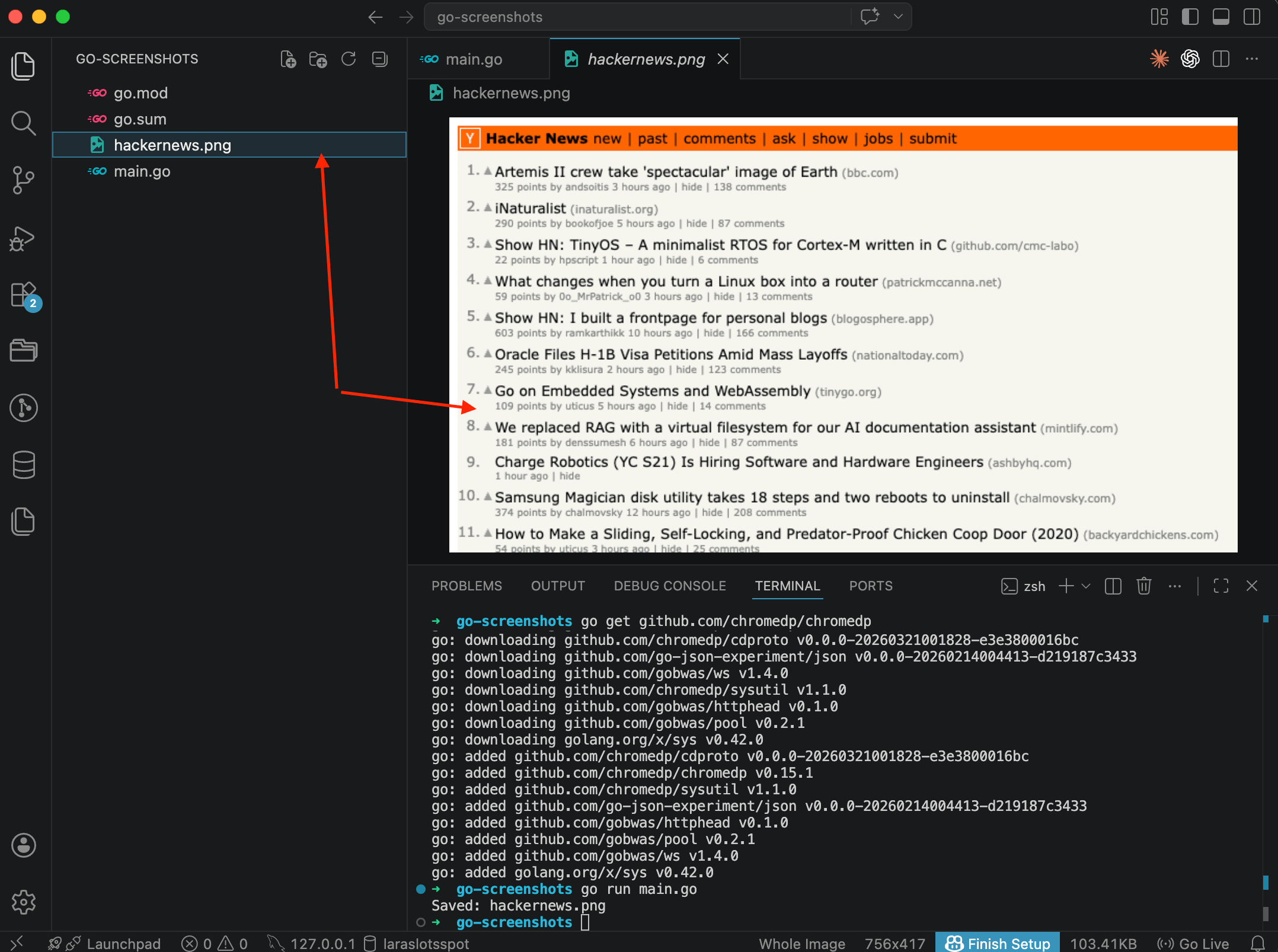
Hacker News with the orange header and list of posts. The screenshot captured only the visible portion, whatever fits in the browser window. Content below the viewport didn't make it into the image. The dimensions are 756x417, which is chromedp's default viewport (800x600 minus Chrome UI). For most tasks that's too small, but we'll fix that next.
Full-page screenshot
Usually you need the entire page, from top to bottom. chromedp handles this with FullScreenshot:
package main
import (
"context"
"fmt"
"log"
"os"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var buf []byte
if err := chromedp.Run(ctx,
chromedp.Navigate("https://news.ycombinator.com"),
chromedp.FullScreenshot(&buf, 100),
); err != nil {
log.Fatal(err)
}
if err := os.WriteFile("hackernews_full.png", buf, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: hackernews_full.png")
}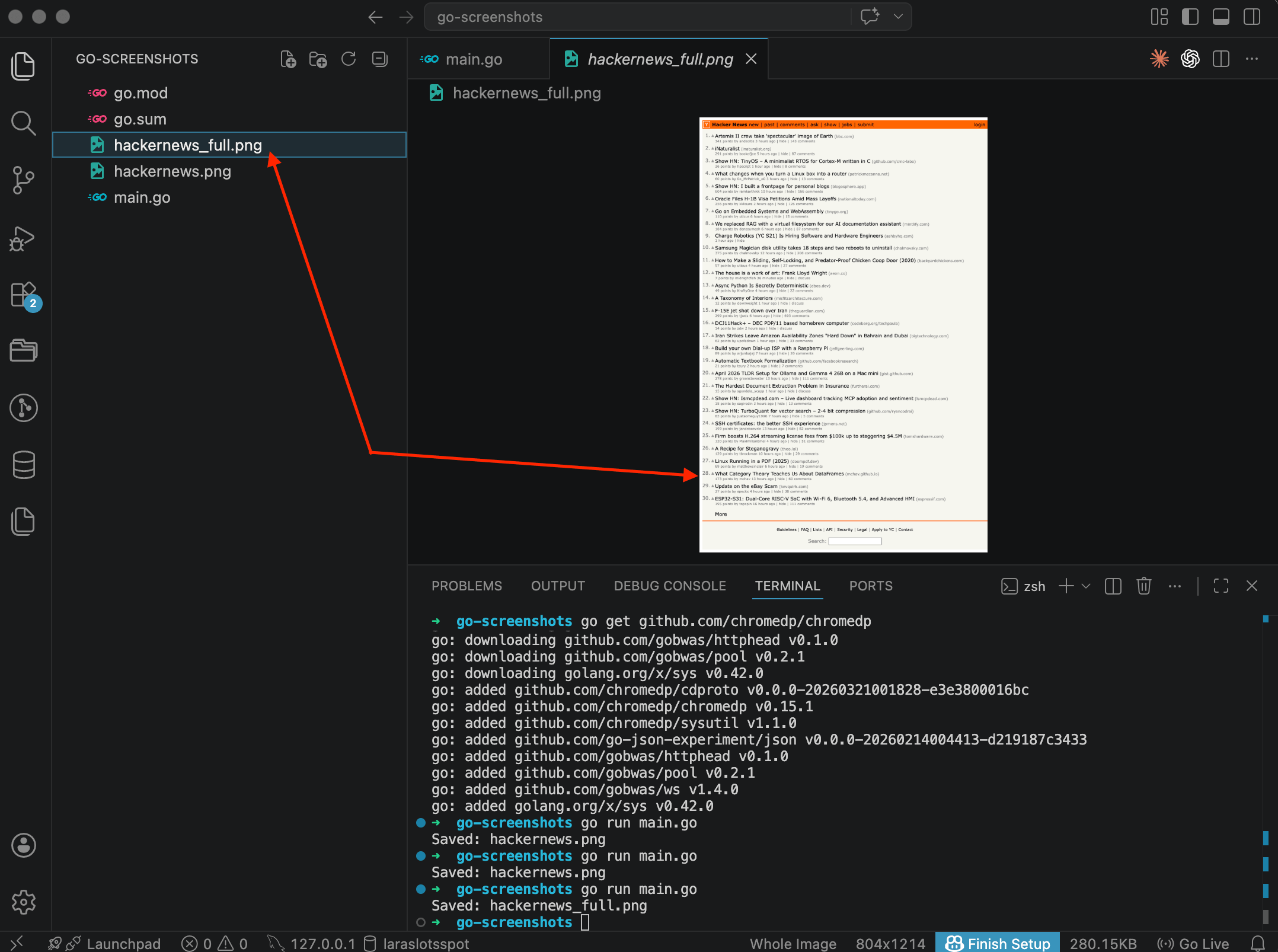
The difference is obvious right away. The image is much taller now, from the header all the way down to the footer. All 30 posts, navigation links, the search bar at the bottom. In the VS Code preview you can see the entire page captured in one shot.
The 100 parameter is the image quality. When the value is 100, chromedp saves as PNG. Anything below 100 switches to JPEG. Easy to miss in the docs, but it matters.
Custom viewport
By default chromedp uses an 800x600 viewport. For most websites that's too narrow, and the layout might switch to a tablet or even mobile breakpoint. To set the size you want, use chromedp.EmulateViewport:
package main
import (
"context"
"fmt"
"log"
"os"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var buf []byte
if err := chromedp.Run(ctx,
chromedp.EmulateViewport(1920, 1080),
chromedp.Navigate("https://github.com"),
chromedp.CaptureScreenshot(&buf),
); err != nil {
log.Fatal(err)
}
if err := os.WriteFile("github_1080p.png", buf, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: github_1080p.png")
}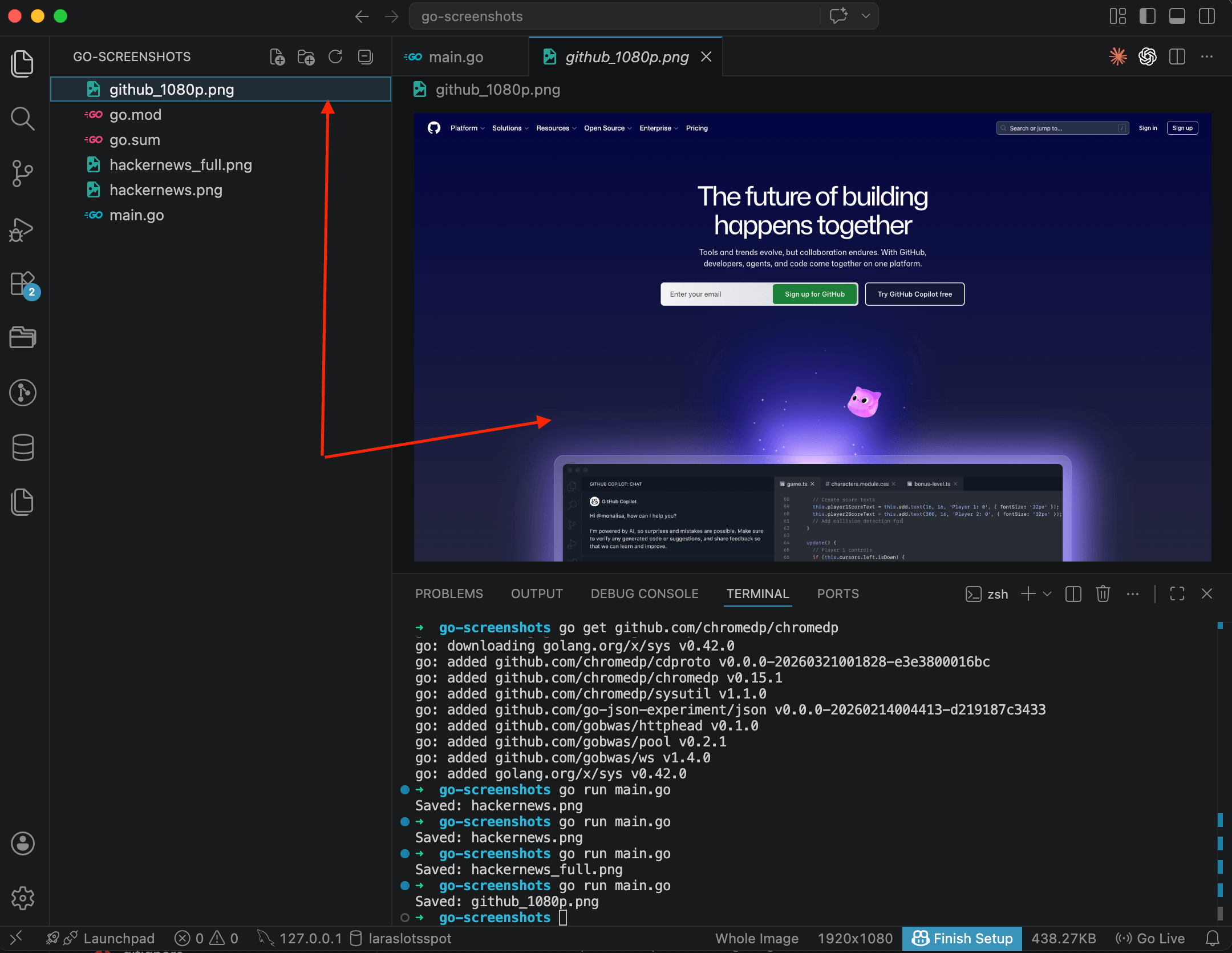
Now the page renders at full 1920x1080 pixels. GitHub shows the desktop navigation, search bar, Copilot section, everything you'd see on a real monitor. Compare this with the earlier screenshots at the default 800x600 and the difference is clear.
One thing to remember: call EmulateViewport before Navigate. If you call it after, the page is already rendered with the default viewport, and CSS media queries won't recalculate.
Mobile screenshot
For mobile emulation you need more than just a smaller viewport. You also have to set the device scale factor and a mobile user-agent string. chromedp supports this through the emulation package:
package main
import (
"context"
"fmt"
"log"
"os"
"github.com/chromedp/cdproto/emulation"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var buf []byte
if err := chromedp.Run(ctx,
chromedp.ActionFunc(func(ctx context.Context) error {
return emulation.SetDeviceMetricsOverride(390, 844, 3.0, true).Do(ctx)
}),
chromedp.ActionFunc(func(ctx context.Context) error {
return emulation.SetUserAgentOverride(
"Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1",
).Do(ctx)
}),
chromedp.Navigate("https://github.com"),
chromedp.CaptureScreenshot(&buf),
); err != nil {
log.Fatal(err)
}
if err := os.WriteFile("github_mobile.png", buf, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: github_mobile.png")
}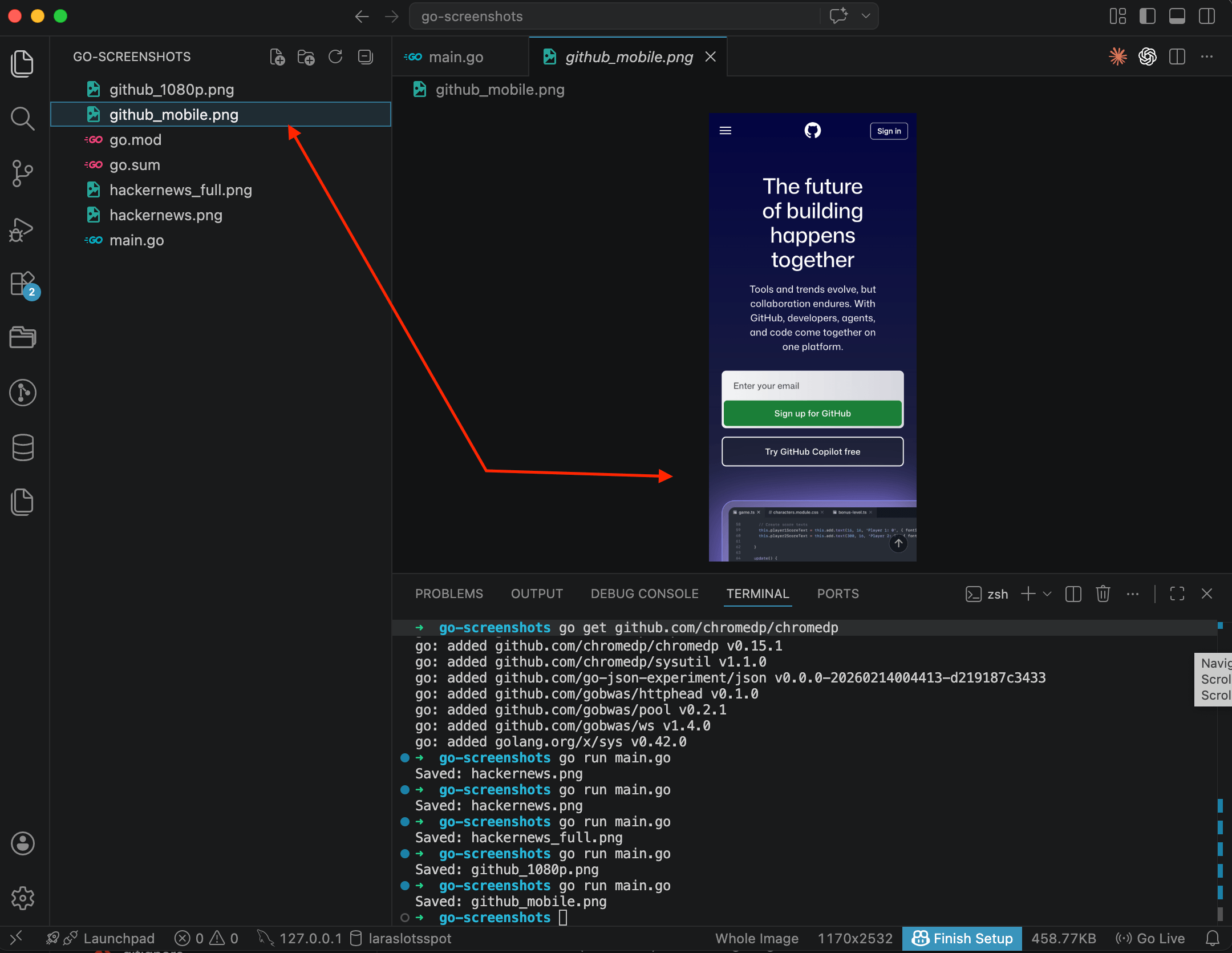
GitHub in mobile view: hamburger menu instead of the full navigation bar, vertical layout, touch-friendly "Sign up" and "Sign in" buttons. In the VS Code status bar you can see the dimensions, 1170x2532. That's 390x844 multiplied by the 3.0 device pixel ratio.
There's more code here than in Playwright, where you'd just write devices['iPhone 14']. In chromedp you manually specify width (390), height (844), pixel ratio (3.0), and the mobile flag (true). And the user-agent string goes separately. Not the most convenient setup, but you get full control over exactly what's being emulated.
Element screenshot
Sometimes you don't need the whole page, just one specific block: a form, a product card, a navigation bar. chromedp can capture a single element by its CSS selector:
package main
import (
"context"
"fmt"
"log"
"os"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var buf []byte
if err := chromedp.Run(ctx,
chromedp.Navigate("https://news.ycombinator.com"),
chromedp.Screenshot("table", &buf, chromedp.NodeVisible),
); err != nil {
log.Fatal(err)
}
if err := os.WriteFile("hackernews_table.png", buf, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: hackernews_table.png")
}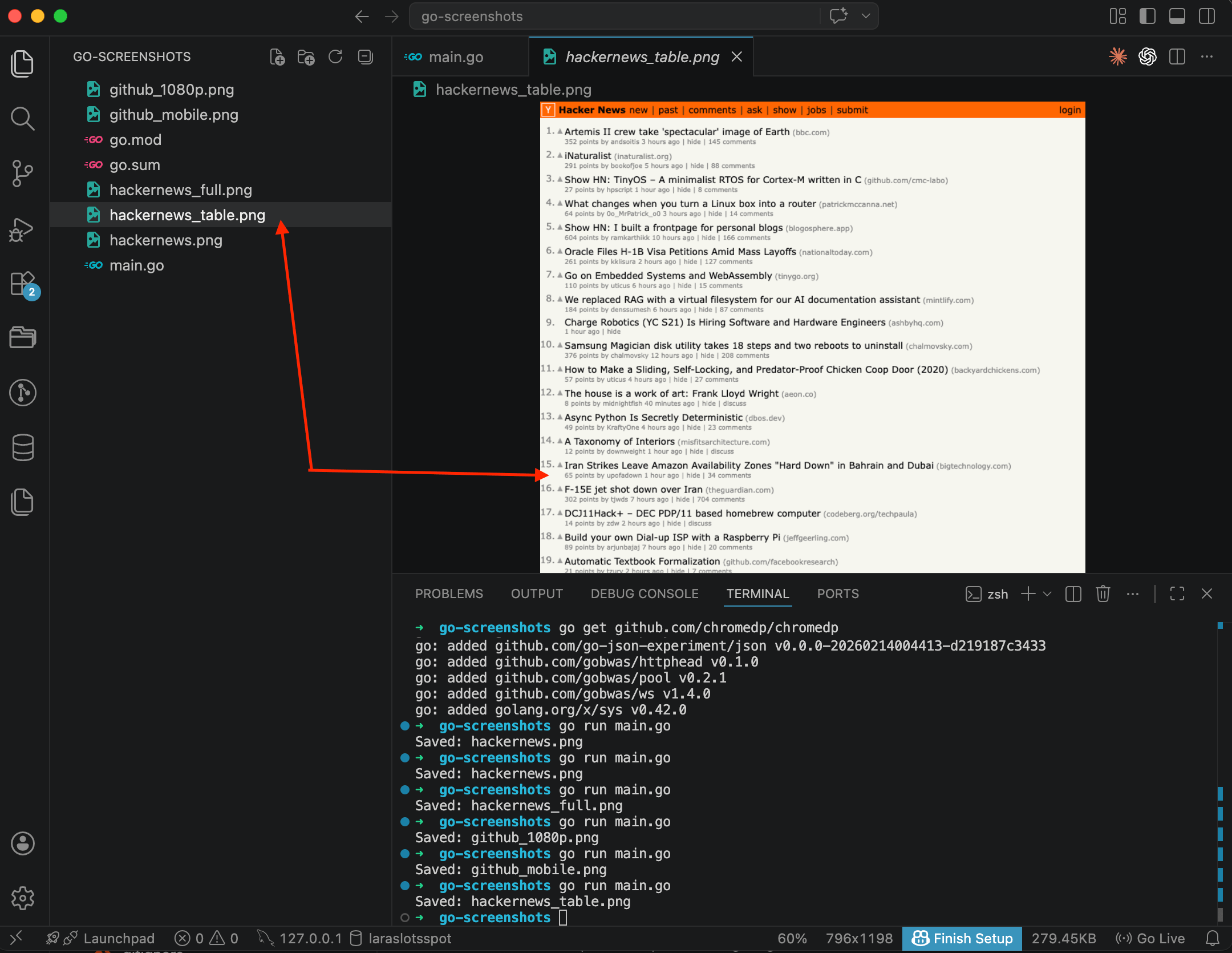
The result is just the Hacker News content: the list of posts with scores, authors, and comment counts. No extra whitespace, no footer. chromedp.Screenshot takes a CSS selector, a buffer, and the chromedp.NodeVisible option, which tells it to wait until the element is actually visible before capturing.
This is handy for monitoring: you can take a screenshot of a specific widget on a schedule and compare results over time. I wrote a separate post about capturing specific elements with CSS selectors if you want to go deeper.
Waiting for content to load
One of the most common problems: the screenshot fires before the page finishes loading. Dynamic content, lazy images, data fetched from APIs. All of that might not render in time.
chromedp gives you a few ways to wait:
// Wait for a specific element to appear
chromedp.WaitVisible(".main-content"),
// Wait until the element is in the DOM
chromedp.WaitReady("body"),
// Just wait (not ideal, but sometimes necessary)
chromedp.Sleep(3 * time.Second),The most reliable option is WaitVisible with a CSS selector that you know exists on the fully loaded page. Sleep is a last resort for cases when you don't know which specific element to wait for.
Where chromedp gets awkward
After working with chromedp for a while, I ran into a few things worth mentioning.
Cookie banners. Same story as Playwright and Puppeteer. There's no built-in way to remove them. You can write JavaScript to click an "Accept" button or hide the banner with CSS injection, but every site has its own markup. At scale this turns into an endless game of adding new selectors. I wrote up the layered approach I ended up using (network blocking, CSS injection, and click-accept fallback) in a separate post on hiding cookie banners, ads, and chat widgets in screenshots.
No device list. Playwright ships a ready-made list of devices with the correct viewport, DPR, and user-agent for each one. In chromedp you set everything by hand. Fine for one or two devices. For ten, you'll want to build a wrapper.
Memory. Each Chrome instance eats 200-400 MB of RAM. If you need 10 parallel screenshots, that's 2-4 GB right there. chromedp doesn't manage a browser pool for you, so that's on you to build.
Fonts on servers. Headless Chrome on a Linux server doesn't have the same fonts as your Mac. Screenshots in production will look different. You'll need to install font packages manually: fonts-liberation, fonts-noto for CJK support. By the time you're juggling browser pools, fonts, selector lists and memory tuning, it's worth asking whether running this yourself is still the right call. I wrote a longer take on when to build vs buy a screenshot stack.
Method 2: Screenshot API
If you want to skip the whole Chrome-on-a-server situation (the memory management, the cookie banner hacks, the font packages), there's another way. Send an HTTP request with a URL, get a finished screenshot back. All the rendering happens on the service side.
I'll show this using ScreenshotRun, an API I built for exactly this kind of task. The free plan gives you 200 requests per month, which is enough to try things out.
First, sign up and grab your API key from the dashboard.
Basic request
package main
import (
"fmt"
"io"
"log"
"net/http"
"net/url"
"os"
)
func main() {
apiKey := "your-api-key-here"
params := url.Values{}
params.Set("url", "https://github.com")
params.Set("format", "png")
params.Set("width", "1280")
params.Set("height", "800")
params.Set("response_type", "image")
reqURL := "https://api.screenshotrun.com/v1/screenshots/capture?" + params.Encode()
req, err := http.NewRequest("GET", reqURL, nil)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Authorization", "Bearer "+apiKey)
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
body, _ := io.ReadAll(resp.Body)
log.Fatalf("Error %d: %s", resp.StatusCode, string(body))
}
data, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
if err := os.WriteFile("github_api.png", data, 0644); err != nil {
log.Fatal(err)
}
fmt.Println("Saved: github_api.png")
}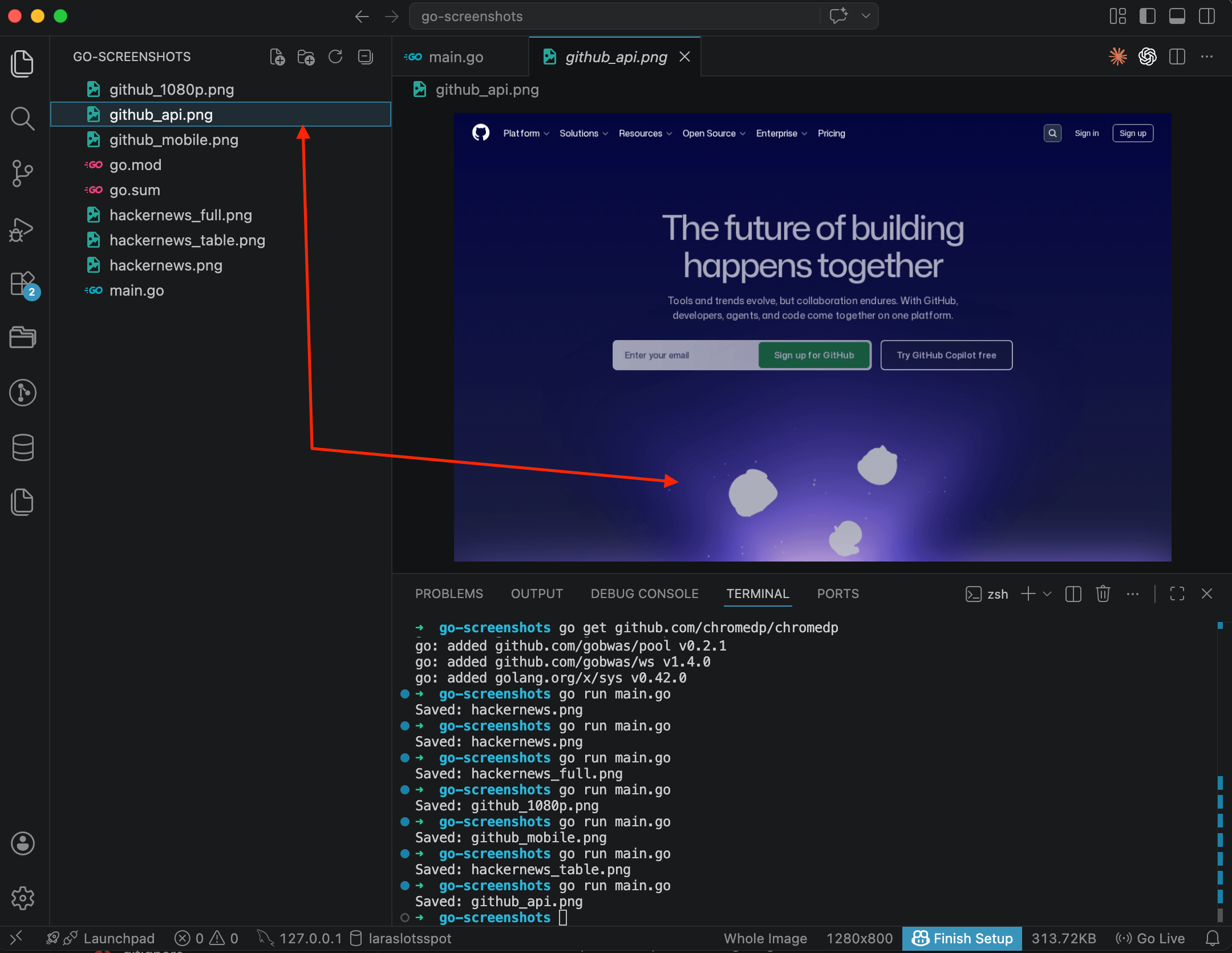
Same GitHub page, but this time through the API. No Chromium, no drivers. One HTTP request, one file. Everything here uses the Go standard library, no external dependencies at all. The response_type=image parameter tells the API to return the binary image directly, without a JSON wrapper.
In the terminal you can see the trail of every script we ran: hackernews.png, hackernews_full.png, github_1080p.png, github_mobile.png, hackernews_table.png, and now github_api.png.
If you want to try the same thing from the terminal without writing any code, check out my guide on taking screenshots with cURL.
Full-page screenshot via API
Add one parameter:
params := url.Values{}
params.Set("url", "https://github.com/topics")
params.Set("format", "png")
params.Set("width", "1280")
params.Set("full_page", "true")
params.Set("response_type", "image")The API scrolls the page on its own, waits for lazy-loaded images to appear, and assembles the full snapshot. You don't need to think about scroll logic or timeouts. That's all handled on the service side.
Mobile screenshot via API
params := url.Values{}
params.Set("url", "https://stripe.com")
params.Set("format", "png")
params.Set("width", "390")
params.Set("height", "844")
params.Set("response_type", "image")Width 390 and height 844 match the iPhone 14 screen. You can emulate any mobile viewport the same way, just change the numbers.
Batch processing multiple URLs
This is where the API approach pays off most. Say you need to screenshot several websites at once:
package main
import (
"fmt"
"io"
"net/http"
"net/url"
"os"
"strings"
)
func main() {
apiKey := "your-api-key-here"
urls := []string{
"https://github.com",
"https://stackoverflow.com",
"https://dev.to",
"https://news.ycombinator.com",
"https://producthunt.com",
}
os.MkdirAll("screenshots", 0755)
for _, targetURL := range urls {
domain := strings.ReplaceAll(
strings.TrimPrefix(
strings.TrimPrefix(targetURL, "https://"),
"http://",
),
".", "_",
)
params := url.Values{}
params.Set("url", targetURL)
params.Set("format", "png")
params.Set("width", "1280")
params.Set("height", "800")
params.Set("response_type", "image")
reqURL := "https://api.screenshotrun.com/v1/screenshots/capture?" + params.Encode()
req, _ := http.NewRequest("GET", reqURL, nil)
req.Header.Set("Authorization", "Bearer "+apiKey)
resp, err := http.DefaultClient.Do(req)
if err != nil {
fmt.Printf("✗ %s: %v\n", domain, err)
continue
}
if resp.StatusCode == 200 {
data, _ := io.ReadAll(resp.Body)
os.WriteFile(fmt.Sprintf("screenshots/%s.png", domain), data, 0644)
fmt.Printf("✓ %s\n", domain)
} else {
fmt.Printf("✗ %s: %d\n", domain, resp.StatusCode)
}
resp.Body.Close()
}
fmt.Println("\nDone. Check screenshots/")
}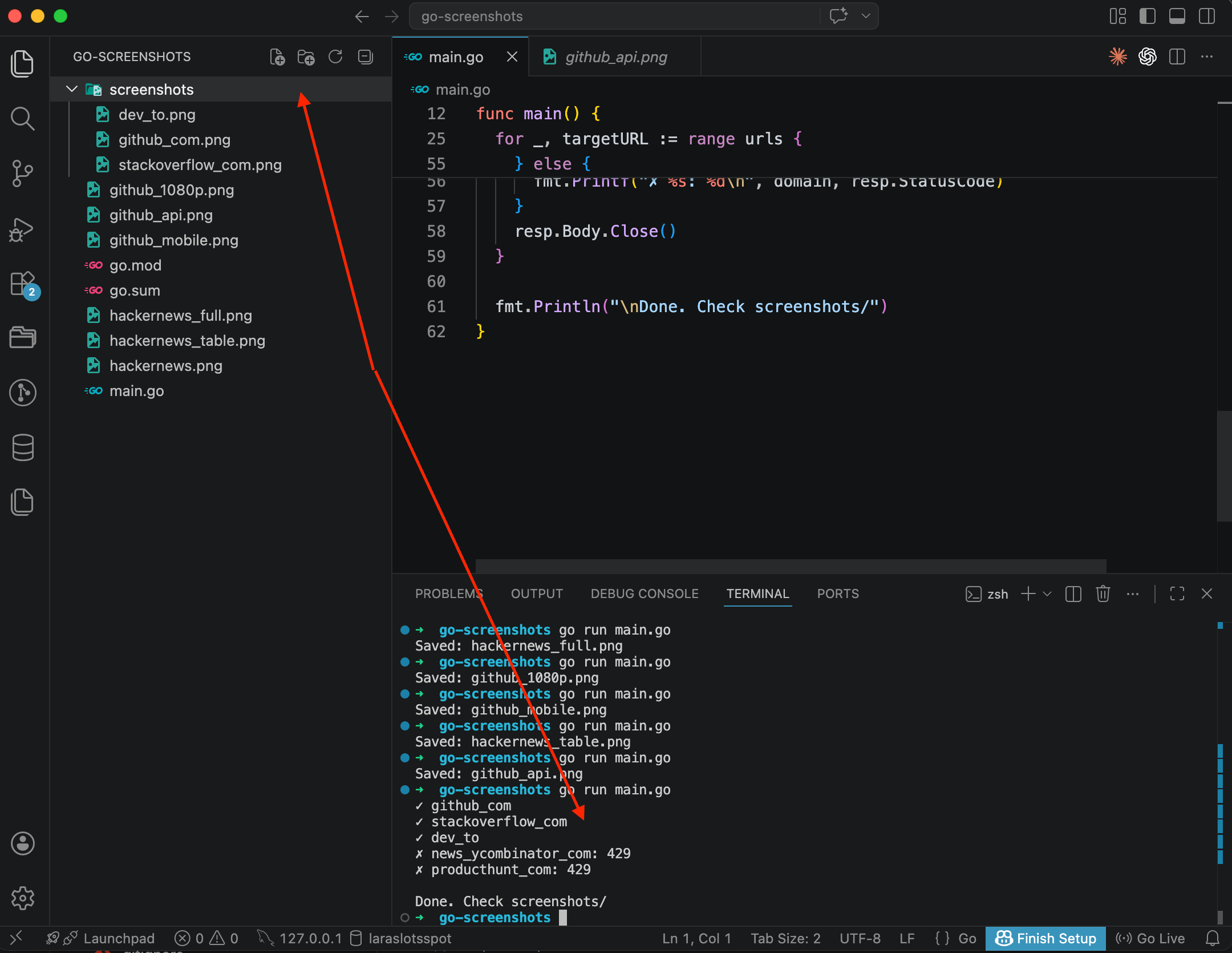
Three out of five went through: github_com, stackoverflow_com, dev_to. But news_ycombinator_com and producthunt_com came back with a 429, which is a rate limit. I was testing this on the free plan with a test account, and the per-minute request limit kicked in by the fourth URL. I decided not to redo the screenshot and show it as-is, so you'd know what to expect if the same thing happens to you.
There are two ways around this. The simple one: add time.Sleep(2 * time.Second) between requests to space them out. The other: upgrade to a paid plan where the limits are higher. The free tier's 200 requests per month is plenty for testing, but fast sequential requests will hit the per-minute ceiling.
Five sites, five files, all through the standard library. With chromedp you'd have to start and stop a browser for each URL. With the API, each request is just a regular HTTP call.
Goroutines for parallel screenshots
If you need to speed things up and you're on a paid plan with higher rate limits, you can use goroutines:
package main
import (
"fmt"
"io"
"net/http"
"net/url"
"os"
"strings"
"sync"
)
func main() {
apiKey := "your-api-key-here"
urls := []string{
"https://github.com",
"https://stackoverflow.com",
"https://dev.to",
"https://news.ycombinator.com",
"https://producthunt.com",
}
os.MkdirAll("screenshots", 0755)
var wg sync.WaitGroup
sem := make(chan struct{}, 3) // max 3 concurrent requests
for _, targetURL := range urls {
wg.Add(1)
go func(u string) {
defer wg.Done()
sem <- struct{}{}
defer func() { <-sem }()
domain := strings.ReplaceAll(
strings.TrimPrefix(
strings.TrimPrefix(u, "https://"),
"http://",
),
".", "_",
)
params := url.Values{}
params.Set("url", u)
params.Set("format", "png")
params.Set("width", "1280")
params.Set("height", "800")
params.Set("response_type", "image")
reqURL := "https://api.screenshotrun.com/v1/screenshots/capture?" + params.Encode()
req, _ := http.NewRequest("GET", reqURL, nil)
req.Header.Set("Authorization", "Bearer "+apiKey)
resp, err := http.DefaultClient.Do(req)
if err != nil {
fmt.Printf("✗ %s: %v\n", domain, err)
return
}
defer resp.Body.Close()
if resp.StatusCode == 200 {
data, _ := io.ReadAll(resp.Body)
os.WriteFile(fmt.Sprintf("screenshots/%s.png", domain), data, 0644)
fmt.Printf("✓ %s\n", domain)
} else {
fmt.Printf("✗ %s: %d\n", domain, resp.StatusCode)
}
}(targetURL)
}
wg.Wait()
fmt.Println("\nDone.")
}The sem channel acts as a semaphore, limiting concurrency to 3 goroutines at a time. This keeps you from hitting the API rate limit. On paid plans you can bump that number up.
This is one of the things I like about Go for these tasks: concurrency through goroutines and channels feels natural, not like a workaround bolted on top of an event loop.
chromedp vs Screenshot API: when each one fits
chromedp
When it fits: you have a Go project and need screenshots occasionally. Everything runs locally or on a server where Chrome is already installed. You need full control: clicking buttons, filling forms, interacting with the page before capturing.
Pros: zero external dependencies (pure Go), direct CDP access (you can do anything Chrome can do), no reliance on third-party services, free.
Cons: Chrome must be installed on your server, each Chrome instance eats 200-400 MB of RAM, no built-in cookie banner handling, default viewport is 800x600 (easy to forget), fonts on Linux servers need manual installation, no built-in device list for mobile emulation.
Screenshot API
When it fits: production, automation, server-side scripts. When you don't want to deal with browser installation and resource management. When you need stability and predictability.
Pros: zero dependencies on your side, just the Go standard library, works on any platform with an HTTP client, doesn't consume your server's RAM or CPU, easy to scale, the API handles cookie banners, lazy loading, and JavaScript rendering on its own.
Cons: you depend on an external service, so if the API goes down, no screenshots. The free plan is limited (200 requests/month on ScreenshotRun). There's a small network delay, each request takes 3-10 seconds. Paid plans for higher volumes start at $9/month. You can't interact with the page (click, log in), it's screenshot-by-URL only.
Comparison table
| chromedp | Screenshot API | |
|---|---|---|
| Setup | go get + Chrome | Nothing (HTTP) |
| Dependencies | Chrome/Chromium | None |
| Default viewport | 800x600 | 1280x800 |
| Full-page screenshot | Yes | Yes |
| Cookie banners | Manual | Automatic |
| Fonts on Linux | Install yourself | Handled |
| Scaling | Your infra | Handled |
| Cost | Free (+ server costs) | Free tier, then paid |
| Concurrency | Goroutines + pool | Goroutines + HTTP |
Production gotchas I wish I'd known earlier
A few things I figured out along the way.
Timeouts. Always set a context timeout for chromedp. Without one, a hanging page will block your application forever:
ctx, cancel := context.WithTimeout(ctx, 30*time.Second)
defer cancel()HTTP client timeout. Same goes for API requests. The default http.DefaultClient has no timeout, so a request could hang indefinitely:
client := &http.Client{Timeout: 60 * time.Second}
resp, err := client.Do(req)File format. In chromedp: quality 100 = PNG, below 100 = JPEG. With the API: pass format=png, format=jpeg, or format=webp explicitly.
Headless mode. chromedp runs Chrome in headless mode by default. If you need to see what's happening (for debugging), you can turn it off:
opts := append(chromedp.DefaultExecAllocatorOptions[:],
chromedp.Flag("headless", false),
)
ctx, cancel := chromedp.NewExecAllocator(context.Background(), opts...)Reuse the browser. Don't create a new context for every screenshot. One browser, multiple tabs. This saves 200+ MB of RAM for each additional screenshot.
Caching. If you're screenshotting the same URLs repeatedly, set up caching. I wrote a separate post about that: how to cache screenshots and stop paying for the same capture twice.
That's the full picture for Go: chromedp when you want full browser control on your own machine, the API when you want zero setup and no infrastructure to maintain. I use both in my own projects, and each one fits a different spot.
If you're not working exclusively in Go, I have similar guides for Python, Node.js, and PHP.

How to handle screenshot API responses in production
A 200 OK from a screenshot API doesn't mean you got a screenshot — the transport and render layers fail independently. Which status codes to retry and which not, backoff with jitter, respecting Retry-After, catching blank images that pass as a 200, and a circuit breaker. Node.js code throughout.
Read more →
Screenshot API rate limiting strategies in production
Most rate limiting guides only cover retry strategies. That's only half the problem. Five concrete strategies — proactive (token bucket, queue) and reactive (Retry-After, exponential backoff, circuit breaker) — with Node.js code.
Read more →
Headless Chrome "net::ERR_CONNECTION_REFUSED" in Docker: causes and fixes
ERR_CONNECTION_REFUSED in headless Chrome inside Docker isn't one error — it's five different network problems sharing the same message. Diagnose with one curl from inside the container, then fix per cause.
Read more →